Unicode 学习记录
文章目录
前段时间有一道不是很难的 Python 沙箱逃逸问题,用到了 Unicode 的 NFKC。这一次详细记录一下 Unicode 里有点意思的特性。
NFKC
利用 NFKC 算是 Python 沙箱逃逸类题目里较为常用的一种方式。在编写攻击载荷时不得不用到某个字符,但是这个字符又被列入了检测的黑名单中,则会利用 Unicode 的 NFKC 标准化,而 Python 恰好也支持 NFKC,这不就巧了嘛!
简单来说,NFKC 可以让程序更好地理解一些字符,它将那些形状类似但是编码不同的字符归为一组字符。例如说在 Unicode 中合字 ffi (U+FB03) 在视觉上等同于 ffi 三个字符拼凑而成,因此需要计算机软件能够识别 ffi 三个字符等同于 ffi 合字字符,以便于用户检索。
因此在 Python 中就会有如下输出:
1print("1" == "1") # U+FF11
2print(int("1") == int("1"))
3
4# output:
5#
6# False
7# True
在下面两个网站里可以找到取代某个 ASCII 字符的 Unicode 字符:
Github - h13t0ry/UnicodeToy: Unicode fuzzer for various purposes
List of Unicode Characters of Bidirectional Class “European Number”
看下面一道例题:
1from secret import flag
2data = input('> ')
3assert len(data) <= 9 and all(i not in '123456789' for i in data) and int(data) == 123456789
4print(flag)
看上去不是很麻烦。题目会在远程服务器上运行,secret 模块及其中的 flag 常量都存储在远程服务器上。 如果我们输入的 data 能够满足这个 assert 中的条件,flag 就会自己跳出来。
条件如下:
-
data 的长度小于等于 9
-
data 中不含 “123456789” 中的任意一个字符
-
data 转化为整型后与 123456789 相等
根据上面提到的内容,我们知道这道题需要利用 NFKC 得到正确的输入,不妨用下述代码遍历:
1// filename: Exp_123456789
2
3public class Exp_123456789 {
4 public static void main(String[] args) {
5 // superscript numbers
6 System.out.printf("%c%c%c", '\u00B9', '\u00B2', '\u00B3');
7 for(char i = '\u2074'; i <= '\u2079'; i++) {
8 System.out.print(i);
9 }
10 System.out.print('\n');
11 // subscript numbers
12 for(char i = '\u2081'; i <= '\u2089'; i++) {
13 System.out.print(i);
14 }
15 System.out.print('\n');
16 // numbers with full stop
17 for(char i = '\u2488'; i <= '\u2490'; i++) {
18 System.out.print(i);
19 }
20 System.out.print('\n');
21 //full width numbers
22 for(char i = '\uFF11'; i <= '\uFF19'; i++) {
23 System.out.print(i);
24 }
25 }
26}
27
28/*
29output:
30¹²³⁴⁵⁶⁷⁸⁹
31₁₂₃₄₅₆₇₈₉
32⒈⒉⒊⒋⒌⒍⒎⒏⒐
33123456789
34*/
其实这段代码用 Python 实现更为方便,为了锻炼 Java 能力就先这么写了。不过后面判断哪一组数据符合条件,依然要使用 Python:
1code = "assert len(data) <= 9 and all(i not in '123456789' for i in data) and int(data) == 123456789"
2try:
3 data = "¹²³⁴⁵⁶⁷⁸⁹" # superscript numbers
4 exec(code)
5 print(data)
6except:
7 try:
8 data = "₁₂₃₄₅₆₇₈₉" # subscript numbers
9 exec(code)
10 print(data)
11 except:
12 try:
13 data = "⒈⒉⒊⒋⒌⒍⒎⒏⒐" # numbers with full stop
14 exec(code)
15 print(data)
16 except:
17 data = "123456789" # full width numbers
18 exec(code)
19 print(data)
20
21# output: 123456789
宽字符赢得了比赛!
零宽字符隐写
前几天想用零宽字符给述职报告凑字数,然后知道了这个东西。不妨先看看零宽字符是什么个东西。通俗来讲,零宽字符就是“宽度为 0 的字符”,一般在从右向左书写的语言以及字与字之间有连笔的语言,如阿拉伯语。下面是一个零宽字符的例子:
1string = "A" + "\u200C\u200C\u200D\u200D" + "b"
2print(string)
3print(len(string))
4
5# output:
6#
7# Ab
8# 6
在上面的例子中,我们用到了 U+200C 与 U+200D 这两个零宽字符,它们分别是 “断字符” 和 “连字符”,用于控制阿拉伯语的连笔,故在英文语境下不会被打印出来。下面这张表是 Unicode 中全部零宽字符:
| 编码 | 描述 |
|---|---|
| U+200A | ZERO WIDTH SPACE |
| U+200B | ZERO WIDTH SPACE |
| U+200C | ZERO WIDTH NON-JOINER |
| U+200D | ZERO WIDTH JOINER |
| U+200E | LEFT-TO-RIGHT MARK |
| U+200F | LEFT-TO-RIGHT MARK |
| U+202A | LEFT-TO-RIGHT EMBEDDING |
| U+202C | POP DIRECTIONAL FORMATTING |
| U+202D | LEFT-TO-RIGHT OVERRIDE |
| U+2062 | INVISIBLE TIMES |
| U+2063 | INVISIBLE SEPARATOR |
| U+FEFF | ZERO WIDTH NO-BREAK SPACE |
如果一段文本中夹杂了零宽字符,一般的文本编辑器无法显示,但是放入 Cyberchef 或者 Vim 中就能看到了。用上面的 "Ab" 举例子:
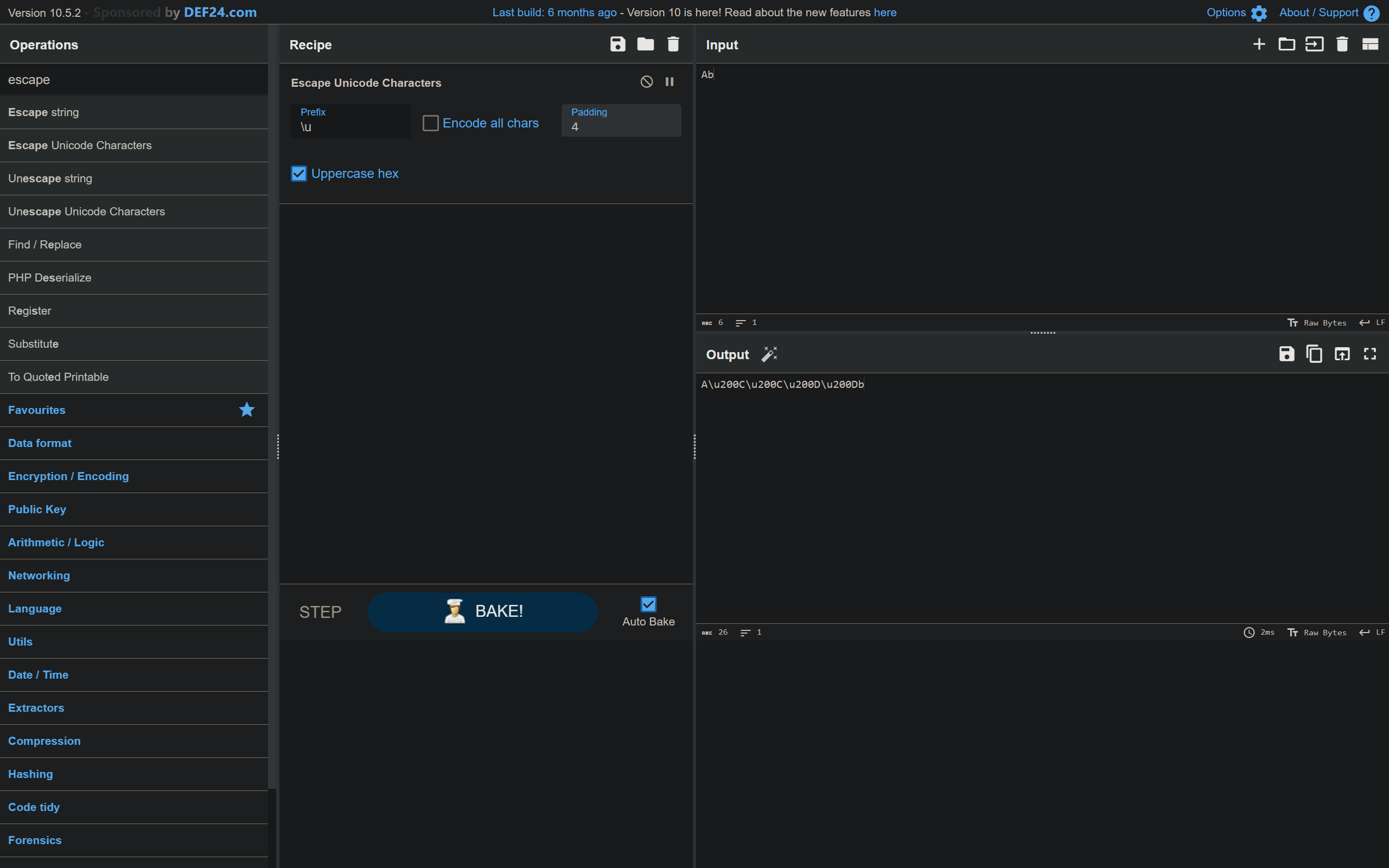
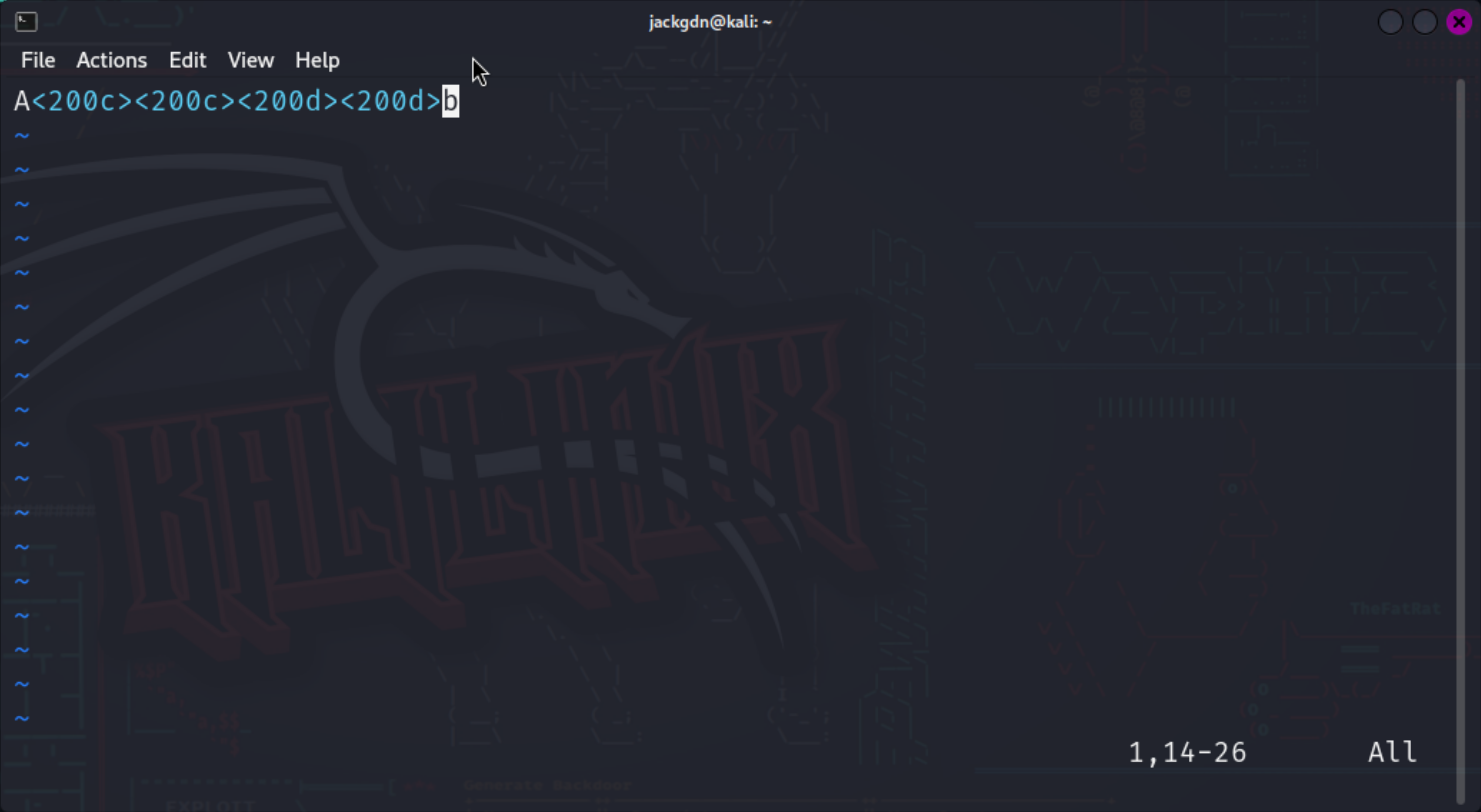
那么什么是零宽字符隐写呢?零宽字符隐写将密文对应的编码转化为不同的零宽字符,并将其混杂在正常的文本中。例如说,我使用 U+200C 与 U+200D 两种零宽字符作为用于加密,我可以令 U+200C 对应二进制 0,U+200D 对应二进制 1。下面这段代码,将 "Meschenrechte" 这个单词隐写入 "Hello, World!" 这句话中:
1print("Hello, World", end = '')
2secret = "Meschenrechte"
3
4for i in secret:
5 s = str(bin(ord(i)))[2:]
6 print("\u200C", end = '')
7 for k in s:
8 if k == "0":
9 print("\u200C", end = '')
10 else:
11 print("\u200D", end = '')
12
13print("!")
14
15# output: Hello, World!
在这一样例程序,我们只是把密文转换成 U+200C 与 U+200D 两种零宽字符并全部放入了 'd' 与 '!' 之间的位置。然而在实际操作中,密文可以使用其他几种零宽字符、使用其他编码格式、打乱顺序等等。由此可见,零宽字符隐写并没有一个统一的标准,我可以用任意的符号来代替一种编码,因此实际上零宽字符隐写最大的优势在于它看不见。正是出于这个原因,我认为 2023 安洵杯“疯狂的麦克斯”一题并不严谨。有许多在线工具可以进行零宽字符的加密与解密,安洵杯中使用的是这个:
Unicode Steganography with Zero-Width Characters
哦对了,还需要一个解密脚本,对应我自己设计的隐写脚本:
1text = "Hello, World!"
2cip = text[12: -1]
3
4for i in range(0, 104, 8):
5 seg = cip[i: i + 8]
6 dat = 0
7 for k in range(0, 8):
8 if seg[k] == "\u200D":
9 dat = dat + 2**(7 - k)
10 print(chr(dat), end = '')
11
12# output: Meschenrechte
试了一下,我自己的隐写脚本得到的结果,拖到那个网站里解密会失败 (っ °Д °;)っ
Unicode 中的零宽字符早已被人们开发出更多的用途,例如添加文字水印防止剽窃、反爬虫摸出关键字防止屏蔽或者给文章凑字数。
Unicode 附加字符
这个似乎与 CTF 的关系并不大,但是也挺有意思。演示一下:
̀́̂̃̄̅̆̇̈ ̉̊̋̌̍̎̏̐̑ ̖̗̘̙̒̓̔̕̚ ̡̢̛̜̝̞̟̠̣ ̧̨̤̥̦̩̪̫̬ ̴̵̭̮̯̰̱̲̳ ̶̷̸̹̺̻̼̽̾ ͇̿̀́͂̓̈́͆ͅ ͈͉͍͎͊͋͌͏͐ ͓͔͕͖͙͑͒͗͘ ͚͛͜͟͢͝͞͠͡ ͣͤͥͦͧͨͩͪͫ ͬͭͮͯ
这一坨是 Unicode 中的一些附加字符堆在一块的样子。附加字符在很多情境下都会被使用,例如:拼音。下面两组字符虽然看上去一样,但是对应的编码不一样。前者使用附加字符实现,后者是微软输入法特殊字符表中的打印字符。
ö:\u006F\u0308
ö:\u00F6
用 Python 就可以打印出附加字符。
1string = ' '
2
3for char in range(0x300, 0x310):
4 string = string + chr(char)
5
6print(string)
7
8
9# output: ̀́̂̃̄̅̆̇̈̉̊̋̌̍̎̏
于是我们得到了一张鬼画符(?)
Unicode 附加字符的优点正如你所看到的一样:更加灵活。
代码混淆
Python 似乎是支持中文变量名的:
1import dis as 蒂斯
2
3def 我再也不学Python了():
4 苹果 = 10
5 香蕉 = 20
6 print(苹果 + 香蕉)
7 print(type(我再也不学Python了))
8
9我再也不学Python了()
10
11蒂斯.dis(我再也不学Python了)
12
13'''
14output:
15
1630
17<class 'function'>
18 38 0 RESUME 0
19
20 39 2 LOAD_CONST 1 (10)
21 4 STORE_FAST 0 (苹果)
22
23 40 6 LOAD_CONST 2 (20)
24 8 STORE_FAST 1 (香蕉)
25
26 41 10 LOAD_GLOBAL 1 (NULL + print)
27 20 LOAD_FAST 0 (苹果)
28 22 LOAD_FAST 1 (香蕉)
29 24 BINARY_OP 0 (+)
30 28 CALL 1
31 36 POP_TOP
32
33 42 38 LOAD_GLOBAL 1 (NULL + print)
34 48 LOAD_GLOBAL 3 (NULL + type)
35 58 LOAD_GLOBAL 4 (我再也不学Python了)
36 68 CALL 1
37 76 CALL 1
38 84 POP_TOP
39 86 RETURN_CONST 0 (None)
40
41'''
这种混淆算是较为一般的混淆,单纯修改变量名而不对运行逻辑进行修改,有些类似于“0O”混淆。但是这不禁让我想到,既然中文能够作为变量名,那么是不是大部分 Unicode 字符都可以当作变量名,甚至包括上文提到的零宽字符!
实际上是不能的。但是零宽字符确实可以用于另一种形式的代码混淆,例如下面这段代码:
1encoded = ""
2exec("".join([chr(int(i.replace('\u200C', '0').replace('\u200D', '1'), 2)) for i in encoded.split('\u200B')]))
3
4# output: Hello, World!
我去,很神奇是不是!其原理也简单,使用零宽度字符隐写的方式将实际要执行的代码(在本案例中是 print("Hello, World!))编码,在执行的过程中再解码,有 SMC 那味。此案例中 encoded 生成的方式如下:
1code = """print('Hello, World!')"""
2encoded = '_' + '\u200B'.join([bin(ord(i))[2:].replace('0','\u200C').replace('1','\u200D') for i in code]) + '_'
3print(encoded)
4
5# output: __
6# 为了便于复制,我在编码的前后各加了一个下划线
UTF-7
UTF-7 编码并不是一种严格的 Unicode 编码。个人认为,这种编码实际上更加类似于 Base64 编码。UTF-7 的出现,是为了满足早期只能传输 7-bit 字符的 SMTP 标准,故现在 UTF-7 编码也正在逐渐被弃用。UTF-7 原理较为简单,下面是一个简单的 UTF-7 与 UTF-8 转化的例子。首先我们拿出待转化的 UTF-8 字符:
绷
然后打印出它的编码的二进制:
1>>> bin(ord('绷'))[2:].rjust(16, '0')
2'0111111011110111'
然后像 Base64 编码那样将其六位一组切开,不够的位置补零。
1>>> ['0111111011110111'.ljust(18, '0')[i: i + 6] for i in range(0, 18, 6)]
2['011111', '101111', '011100']
随后查表。UTF-7 中使用的 Base64 编码表和标准 Base64 编码表有一些区别。UTF-7 使用的编码表并不使用 = 补齐。由此我们可以写出编码转化的最后一步了:
1>>> "".join(['ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'[int(j, 2)] for j in ['011111', '101111', '011100']])
2'fvc'
于是我们得到了 绷 这个汉字的 UTF-7 编码:fvc。
把上面的代码碎片合计一下,我们就能得到获取单个 UTF-8 字符的 UTF-7 编码的代码:
1print("".join(['ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'[int(j, 2)] for j in [bin(ord('绷'))[2:].rjust(16, '0').ljust(18, '0')[i: i + 6] for i in range(0, 18, 6)]]))
2
3# output: fvc
UTF-7 编码有许多例外的情况:
- 62 个数字与英语字母不需要转化;
' ( ) , - . / : ?这九种字符也无需转化。 +被编码做+-。- 每一个区块以
+为开头,-为结尾。
1print("+" + "-+".join(["".join(['ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'[int(j, 2)] for j in [bin(ord(k))[2:].rjust(16, '0').ljust(18, '0')[i: i + 6] for i in range(0, 18, 6)]]) for k in "绷不住了,笑えるwww"]) + "-")
2
3# output: +fvc-+Tg0-+T08-+ToY-+/ww-+exE-+MEg-+MIs-+AHc-+AHc-+AHc-
上面这行代码能且只能标准地编码非 ASCII 编码字符的 UTF-8 编码字符,而不能对 ASCII 编码字符进行标准地编码,因为有近一半的 ASCII 字符的 UTF-7 编码与其 ASCII 编码一致——正如上文提到的那样。Cyberchef 里面带有 UTF-7 的编码和解码工具,并且那一解码工具能够对我这段非标准的编码进行解码。
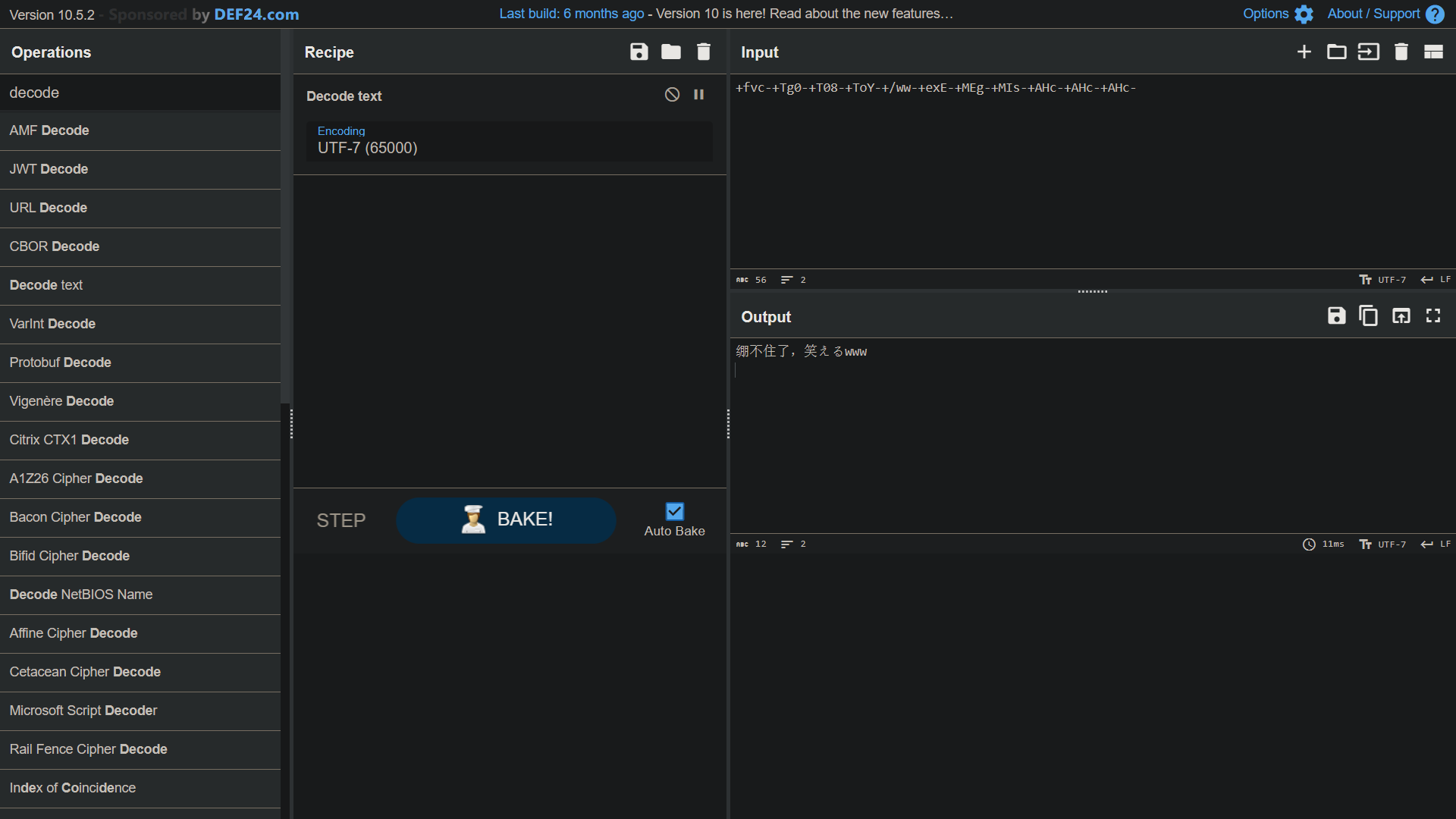
其实硬解也能解码,不是吗?
既然编码代码都有了,那不妨把对应的解码代码造出来吧。还是要优雅地塞到一行里去:
1print("".join([chr(int(int((bin('ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'.index(i[0]))[2:].rjust(6, '0') + bin('ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'.index(i[1]))[2:].rjust(6, '0') + bin('ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'.index(i[2]))[2:].rjust(6, '0'))[: -2], 2))) for i in '+fvc-+Tg0-+T08-+ToY-+/ww-+exE-+MEg-+MIs-+AHc-+AHc-+AHc-'[1:-1].split("-+")]))
2
3# output: 绷不住了,笑えるwww
实际上字符串位置是可以用 input() 的,我们不妨改成更易于在 Python Shell 里运行的代码:
1>>> print("+" + "-+".join(["".join(['ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'[int(j, 2)] for j in [bin(ord(k))[2:].rjust(16, '0').ljust(18, '0')[i: i + 6] for i in range(0, 18, 6)]]) for k in input("> ")]) + "-")
2> 先帝创业未半而骈死于槽枥之间
3+UUg-+Xh0-+Uhs-+Tho-+Zyo-+U0o-+gAw-+mog-+a3s-+To4-+af0-+Z6U-+Tks-+lfQ-
4>>> print("".join([chr(int(int((bin('ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'.index(i[0]))[2:].rjust(6, '0') + bin('ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'.index(i[1]))[2:].rjust(6, '0') + bin('ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'.index(i[2]))[2:].rjust(6, '0'))[: -2], 2))) for i in input("> ")[1:-1].split("-+")]))
5> +UUg-+Xh0-+Uhs-+Tho-+Zyo-+U0o-+gAw-+mog-+a3s-+To4-+af0-+Z6U-+Tks-+lfQ-
6先帝创业未半而骈死于槽枥之间
本段 UTF-7 相关代码纯手搓,Just for fun!
Unicode 与 UTF-8、UTF-16、UTF-32
本来这一段应该是留给 UTF-16 的,但是学习了一些内容之后我感觉我对 UTF-8 也一点都不了解。遂把这些合并到一起去。
这四者的关系,Unicode 是字符集,字符集中的每一个字符都有唯一的编号;后面四者为编码方式,用不同的方式表示出某一个字符。举一个例子:绷 这个字的 Unicode 编号是 U+7EF7,UTF-8 编码是 E7 BB B7,UTF-16LE 编码是 EB AF B7,UTF-32LE 编码是 F1 BB AF A7。
下面这张表列出了你能见到 Unicode 编号以及编码的地方:
| Unicode 编号 | UTF 编码 |
|---|---|
| 形如 U+XXXX 的 | 二进制文本查看器 |
各种编程语言中 \uXXXX 或者 \UXXXXXXXX |
|
各种编程语言中打印 0xXXXX 对应的字符 |
|
Python 中使用 ord() 函数 |
所以说,本文前面的某些内容是不严谨的(我长期错把 Unicode 编号当作 UTF-8 编码) ㄟ( ▔, ▔ )ㄏ
Unicode 与 UTF-8
Unicode 编号范围是 U+0000 到 U+10FFFF,占据字节大小为 1 到 3 个不等。下表展示了 Unicode 编号长度与 UTF-8 编码长度的关系:
| Unicode 编号范围 | UTF-8 编码二进制格式 | UTF-8 编码占据字节数 |
|---|---|---|
| U+00 - U+7F | 0XXXXXXX | 1 |
| U+80 - U+07FF | 110XXXXX 10XXXXXX | 2 |
| U+0800 - U+FFFF | 1110XXXX 10XXXXXX 10XXXXXX | 3 |
| U+010000 - U+10FFFF | 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX | 4 |
0 - 7F 的范围是 ASCII 编码的范围,这一部分 UTF-8 与 ASCII 编码是一致的。在后面的编码中,每个编码由多个字节组成,其中第一个字节前面由若干个连续的 1 和一个 0 开头,这用于告诉计算机,有多少个连续的 1,就说明字符从这一个字节开始,共占据了多少个字节。其后每一个字节都以 10 开头。中间的 X 则使用 Unicode 编号的二进制填充。
例如 绷 这个字,其 Unicode 编号为 U+7EF7,在上表中显然位于第三行。我们先打印出其二进制:
1>>> bin(ord('绷'))[2:].rjust(16, '0')
2‘0111111011110111’
随后按照 4+6+6 的宽度将其切成三份:0111 111011 110111。
然后手动填充格式,得到 UTF-8 编码的二进制:11100111 10111011 10110111
1>>> hex(0b111001111011101110110111)
2'0xe7bbb7'
于是,我们得到了 绷 这个字的 UTF-8 编码:E7 BB B7
需要注意的是,填充那一步需要从右向左填充,因而如果最高位是 0 就可以省略(不然你猜为什么 2 字节 UTF-8 编码中可填充的二进制位只有 11 个)。
Unicode 与 UTF-16
与 UTF-8 一样,UTF-16 也是一种变长字节编码格式。不过 UTF-16 的编码方式更为简单粗暴:
- 对于编号在
U+0000到U+FFFF的字符,直接把编号当作编码,统一占两个字节 - 对于编号在
U+10000到U+10FFFF的字符,先给它减去 0x10000,再填进110110XX XXXXXXXX 110111XX XXXXXXXX
举个例子:兔
如果你复制下来,你会发现它这个字占了四个字节,它的 Unicode 编号是 U+2F80E。我在“中日韩兼容表意文字区(CJK Compatibility Ideographs)”复制了这个字符,一些日语汉字会出现在这个区间。使用某些日语输入法打印出来的日语汉字的编码会与中文一样,这一区间用于存储日、韩、越语言中特有或者异形汉字。但是根据 NFKC 标准化,在网页上你是能够直接通过搜索“兔”找到这个字的。
把它转换成 UTF-16,首先将其 Unicode 编号减去 0x10000:
1>>> bin(ord('兔') - 0x10000)[2:].rjust(20, '0')
2'00011111100000001111'
随后按照 2+8+2+8 的宽度将其切成四份:00 01111110 00 00001111。
然后手动填充格式,得到 UTF-16 编码的二进制:11011000 01111110 11011100 00001111
1>>> hex(0b11011000011111101101110000001111)
2'0xd87edc0f'
于是,我们得到了 兔 这个字的 UTF-16 编码:D8 7E DC 0F
UTTF-16 编码是两个字节为一组读取,因此就要考虑字节序的问题。上面这一种为大端序,也就是 UTF-16BE,其小端序存储形式 UTF-16LE 为 7E D8 0F DC。为了区分大小端序,文件开头部分会有 FE FF(大端序)或 FF FE(小端序)的标注。而 UTF-8 编码中,计算机按顺序每次读取一个字节,因此不存在大小端序的问题。
这时聪明的小朋友就要问了,计算机怎么知道这一个字符占了两个字节还是四个字节呢?这就不得不说 Unicode 的巧妙之处了。如果你仔细观察 Unicode 字符集,你会发现 U+D800 到 U+DBFF 被描述为"High Surrogate"(高代理项),U+DC00 到 U+DFFF 被描述为"Low Surrogate"(低代理项)。这两个区间内(连起来就是一个区间)并不存储字符,而这两个区间又分别是 110110XX XXXXXXXX 与 110111XX XXXXXXXX 的范围。因此,当计算机两字节一组读取到 D8 到 DB 中的某个值,就知道这个字符占据四个字节;读取到 DC 到 DF 中某个字节,就知道这两个字节要跟着前面两个字节一块解码。
Unicode 与 UTF-32
UTF-32 是固定宽度编码,每一个编码占据 4 个字节,因此也许是最好理解的一种编码,直接由 Unicode 编号作为编码,因此 UTF-32 也有浪费存储空间的特点。